A small tale on Anti-RE : Part 0
Hey readers, hope everyone is having a pretty great time. After the first blog, I decided to write another on anti-reverse engineering techniques, learning more about these techniques and convey it in this blog at the best way possible. I hope you will enjoy reading this small blog!
# Contents:
- Preface
- Understanding disassembly De-synchronization.
- Understanding Opaque Predicate.
- Resources & Contributors.
- Author’s two cents.
# Preface :
Lately, I have been working on my reverse engineering skills, trying to solve crackme, doing some amount of reversing in my free time. The challenging thing from my point of view based on my small experience is measures taken by software developers which cause delay in reverse engineering, when pressing F5 multiple times, also does not work out. Then, to challenge my skills, I looked for resources and came around this awesome curation of anti-analysis techniques by Thomas Roccia and other fellow researcher Jean known as Unprotect Project . In this blog, I have picked up three anti-analysis techniques and go through them.
# Understanding disassembly De-synchronization :
The first topic for this blog is understanding disassembly de-synchronization, before breaking down this term, a little about disassembly, while a small piece of high level code is boiled down to an executable which contains a phase where assembling instructions using an assembler is performed and many other processes take place, the disassembler just does the opposite that is converting it back to the assembly language by using certain sort of algorithms.

A disassembler is capable of identifying the file type by parsing the file header or the initial bytes of an executable, then it goes ahead parsing the opcodes at the certain address which comes first and then goes ahead converting them to assembly instructions and listing them.
This process is executed using some sort of algorithms, which the disassemblers use while parsing an executable. Some common ones would be Linear Sweep Disassembly & Recursive Disassembly .
Linear Sweep Disassembly is a technique where the disassembler starts from the beginning of the file, now based on the opcodes it goes ahead disassembling them in a streamline manner.
The entire process of which & what , when instruction is being disassembled is maintained by an instruction pointer. Let us take a small example.

Here, when the disassembler first encounters the opcode E9 it goes ahead and checks the target ISA or Instruction Set Architecture for the targeted processor. Then the address which is visible in the above graph view it is inverted to the opposite endianness, and an unconditional jump is made to to the target offset.
A very common problem or challenge this algorithm faces on a regular basis while disassembling is intermingled form of code and data. A lot of times a series of memory pointers to which jumps were made or in simple word an array of memory instructions aka a jmp table which is a part of code, is interpreted as an instruction .

Another common algorithm is the recursive disassembly. In this type of disassembly, this algorithm is slightly different from linear algorithm, in cases where there is a no condition involved such as mov , xor , add , sub and other instructions, the linear sweep algorithm is used, but in cases of conditional branching such as jz , jnz , je the recursive technique is used to cover those areas of code which exist whether the jump is taken or not.
A common type of problem with this algorithm is when there is a little anomaly with the return address, there can be lot of methods, where a program can deviate the usual return type and can jump to a certain part of code without returning to the address of the caller, that time we can encounter problems in accuracy of the disassembly generated. A solid bonus over using recursive disassembly would be linear sweep disassembly mixes up the .code and .data section whereas this algorithm doesn’t make a mistake doing that.
In today’s date, HexRays and other disassembly connoisseurs who have been working to obtain disassembly from an executable without any information loss, have done a very significant job, although we still lag behind in certain areas where the executable challenges both tools and the one using it. After understanding the basics, now let us look at our challenge that is disassembly de-synchronization .
Disassembly de-synchronization is simple terms as it says is to take an advantage of the common algorithm which is used to generate the disassembly in an synchronized manner either in a sequential manner, or through a branching logic. This is normally done by inserting useless code, which mainly contains nop sleds, unusual bunch of arithmetic, some stack operations , UN-necessary jumps to piece of code which just delays the execution or analysis for the reverse engineer.
Now, let us understand with some of the examples!
Case 1 : UN-necessary nop instructions
#include <stdio.h>
int main() {
_asm {
mov eax, 0x12345678
add eax, 0x00000008
}
_asm {
mov ebx, 0x87654321
sub ebx, 0x00000002
}
return 0;
}In this example, this is a very simple code which moves the value 0x12345678 into eax register and 0x00000008is added into the same register, and then the value 0x87654321 is moved into ebx and 0x00000002 is subtracted from ebx. Now, let us use IDA Freeware to check the disassembly.
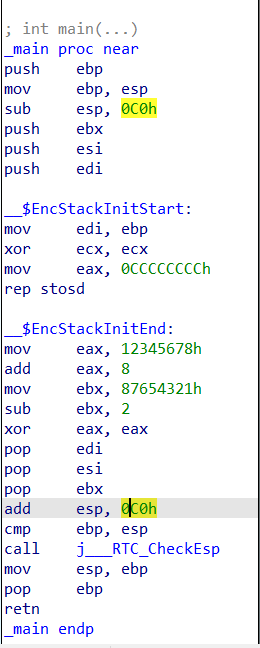
The disassembly appears just exact to the source code and meaningful.
Now, let us add some junk instructions inside the disassembly.
#include <stdio.h>
int main() {
// Original instructions
_asm {
mov eax, 0x12345678
add eax, 0x00000008
}
// Garbage Code
_asm {
nop
nop
nop
}
// Original instructions
_asm {
mov ebx, 0x87654321
sub ebx, 0x00000002
}
return 0;
}Here, we added some bunch of garbage nop instructions, now going back to the basics where we saw that linear sweep algorithm uses a synchronized manner to print out disassembly, in this case, we just used it as an advantage, which will cause complexity(in case of a large scale), more time taken to reverse engineer and figuring out the reason of why are these certain instructions present, which will lead to problems in time taken to reverse engineer the exact subroutine. Now, we will see an example of something complex compared to this example.
Case 2 : Adding UN-necessary loop as garbage code.
#include <stdio.h>
int main() {
// Original instructions
_asm {
mov eax, 0x12345678
add eax, 0x00000008
}
// Garbage Code
_asm {
mov ecx, 0x05
loop_label:
nop
loop loop_label
}
// Original instructions
_asm {
mov ebx, 0x87654321
sub ebx, 0x00000002
}
return 0;
}In this case, the logic of the program is exact to our first program pushing values to the eax , then perform add , pushing value to ebx ,and perform sub . Only extra garbage code has been added which is :
_asm {
mov ecx, 0x05
loop_label:
nop
loop loop_label
}Now, let us load this executable into IDA and check out the disassembly.
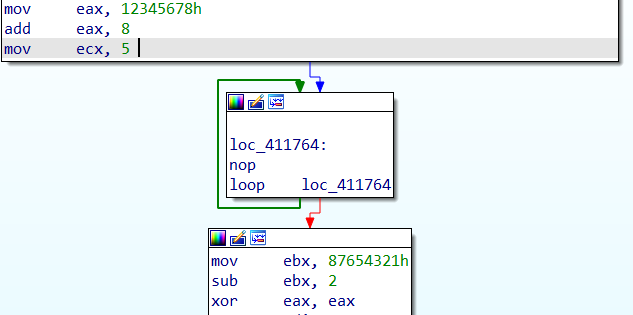
Now, we see that the disassembly is much altered and we have some extra junk code where ecx is set to 5 which will act as a counter variable and after the loop executes, we will get to our original code that is mov ebx, 87654321 . Now, let us check by setting up a break point.
We can see that the loop had to be executed in a linear manner to jump to the original code, which definitely adds up more time to analysis and complexity and raises a doubt regarding the presence of the loop and what it actually had to do in the program.
Case 3 : A garbage loop but slightly complex.
In the past two cases, we saw how garbage code can take an advantage of linear sweep and its synchronized manner of printing out disassembly, this example is just same but with slight changes.
#include <stdio.h>
int main() {
// Original instructions
_asm {
mov eax, 0x12345678
add eax, 0x00000008
}
// Garbage loop & label
_asm {
mov ecx, 0x05
loop_label:
nop
push eax
pop ebx
call subroutine ; calls to garbage subroutine
xor eax, 0x01
dec ecx
jne loop_label
}
// Original instructions
_asm {
mov ebx, 0x87654321
sub ebx, 0x00000002
}
_asm {
subroutine:
push ebx
push eax
add eax, 0x05
add ebx, 0x05
sub eax, 0x05
sub ebx, 0x05
pop eax
pop ebx
ret
}
return 0;
}
In this code, the work of the program is just same as the first one, but instead here, there is more junk code, which calls to another sub-routine, adds & subtracts the same value and returns back the garbage label, and then moves to the actual instruction. Now let us open IDA and check the disassembly of the code.
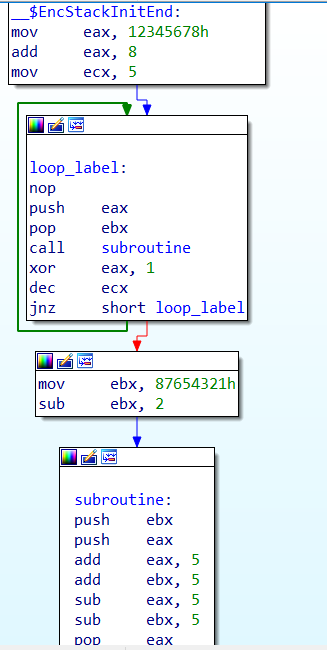
We can see, that the disassembly now looks more complex than the previous one, let us set a break point at the same place where we did at the second case.
In this case, we see the analysis of the program compared to the very first de-synchronized nop sled code is quite more time-taking which solely depends on skill-set of a reverse engineer.
There are no concrete ways, in my knowledge to avoid disassembly-de-synchronization at the go, but this can be dealt with time and flow-analysis of the program, the branches, and in many cases dynamic analysis like this can buy us a little time, compared to static analysis to figure out the main reason behind bunch of garbage jumps, subroutines and help us evaluate the real working of code.
In case, you are still confused or want to explore more opportunities or explanations regarding this technique , you can dive into the IDA Pro Book. Now, without any further delay, let us move ahead to the next topic, which is quite related with this one.
# Understanding Opaque Predicate :
In terms of the first anti-analysis code, this technique resembles at a point that, both are focused on wasting more and more time of a reverse engineer. Now, opaque predicate can simply be understood this way, let’s assume the very first code in the previous technique[disassembly-de-synchronization] which was just adding a value to eax & ebx register. Now, let us take the third case adding bunch of useless loops and subroutine.
Now, sometimes software developers they just try to mold to logic of code by adding more and more garbage code, which obviously will be a part of our analysis, and will consume more time finding the actual working. Now, let us understand it with an example.
#include <stdio.h>
#include <string.h>
int main() {
char input[100];
printf("Enter a string: ");
fgets(input, sizeof(input), stdin);
input[strcspn(input, "\n")] = 0;
printf("Converted string: ");
for (int i = 0; i < strlen(input); i++) {
printf("0x%x ", input[i] + 0xa);
}
printf("\n");
return 0;
}Now, here is a very straight-forward C program which takes an character array as input and iterates through every letter of the array which was saved in input variable, and then it prints the hexadecimal format with the specifier and then it just adds 0xa to the existing hexadecimal equivalent of the alphabet and prints it.
Now, let us compile it and check the disassembly in IDA.

The disassembly seems to be quite straight-forward with 0xa being added to the buffer and then the content is printed in a hexadecimal format, and this loop runs until all the contents of the string entered by the user has been, converted and printed.
Now, let us try to add some garbage code, in it!
#include <stdio.h>
#include <string.h>
int main() {
char input[100];
printf("Enter a string: ");
fgets(input, sizeof(input), stdin);
input[strcspn(input, "\n")] = 0;
int j = 0;
while (j < 10) {
j++;
}
int k = 0;
for (int i = 0; i < 100; i++) {
k++;
}
printf("Converted string: ");
for (int i = 0; i < strlen(input); i++) {
printf("0x%x ", input[i] + 0xa);
}
printf("\n");
return 0;
}In this code, there are two extra loops while & for , which literally does nothing except making the disassembly process complex, by creating a small confusion which branch to jump next, and what exactly would be the purpose? Now, let us load this executable in IDA.
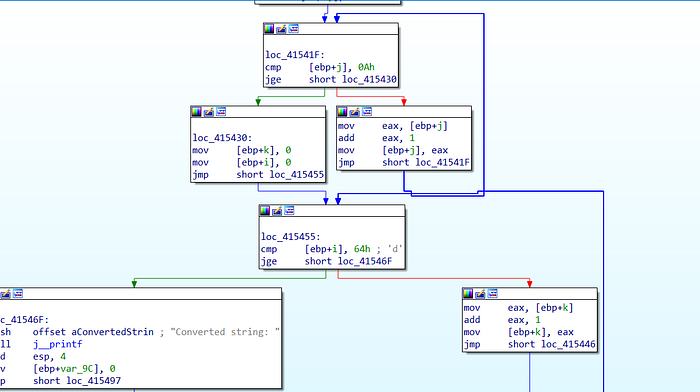
We, can now see that there are multiple branches, which has made the disassembly more time taking to understand , and what actually those loops are. Now, let us set a break-point and check it out!
We can now see, this is hindering the analysis time by executing each and every useless loop, with presence of literally three loops out of which only one was useful, we failed to identify in a linear manner that which was actually important. Now let us look at our last and a bit more interesting example, compared to this one!
#include <stdio.h>
#include <string.h>
void uselessArithmetic(int x) {
int result = 0;
for (int i = 0; i <= x; i++) {
result += i;
}
}
int main() {
char input[100];
printf("Enter a string: ");
fgets(input, sizeof(input), stdin);
input[strcspn(input, "\n")] = 0;
int j = 0;
while (j < 10) {
j++;
}
int k = 0;
for (int i = 0; i < 100; i++) {
k++;
}
uselessArithmetic(100);
printf("Converted string: ");
for (int i = 0; i < strlen(input); i++) {
printf("0x%x ", input[i] + 0xa);
}
printf("\n");
return 0;
}In this case, we added a small function which does nothing except adding all the numbers from 0 to 100, taking 100 as the parameter, and the rest of the code is just as it is, now let us check out the IDA-View for this compiled executable.
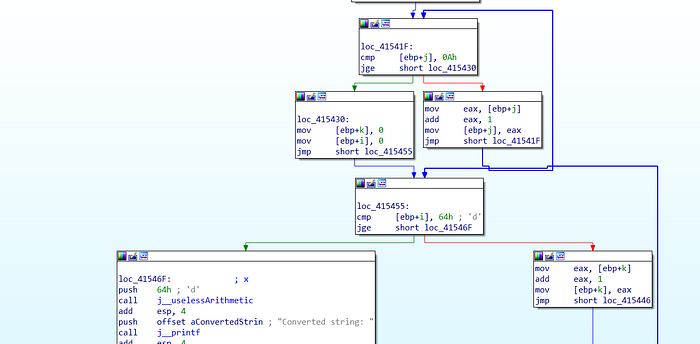
We can now see, that the disassembly of the program looks much more complex than the previous one, it also calls other function j_uselessArithmetic whereas the output for all the three scenarios are just same as usual. Now let us set a break-point and check out!
We can see from this scenario that time was wasted on going through the function uselessArithmetic , which did not even print the result of the addition making no changes to the existing code, but just adding more loops and making tracing the control flow a bit more time taking work.
So, in this small block, I tried to dig the surface of two common problems while doing static analysis using disassemblers, these examples are a go-to ones, if you find something misleading, or anything which could add up, or any kind of feedback, please feel free to drop positive criticism, in the next part, I will be digging the surface for other anti analysis techniques.
# Resources :
- https://unprotect.it
- https://github.com/yellowbyte/analysis-of-anti-analysis/blob/master/research/the_return_of_disassembly_desynchronization/the_return_of_disassembly_desynchronization.md
- https://binary.ninja/2017/10/01/automated-opaque-predicate-removal.html
- https://blogs.vmware.com/security/2019/02/defeating-compiler-level-obfuscations-used-in-apt10-malware.html
- Stack Overflow.
# Author’s two cents :
So, finally I spent my this weekend writing this blog, next weekend I will be writing on something similar, and continue this series of anti-re. Please feel free to let me know, if you find anything misleading or wrong, or better examples, or anything which will help me to improve. Thank you for reading.
# Contributors :

— RIXED LABS Team
